domingo, 3 de set. de 2023
Función de optimización de una red neuronal
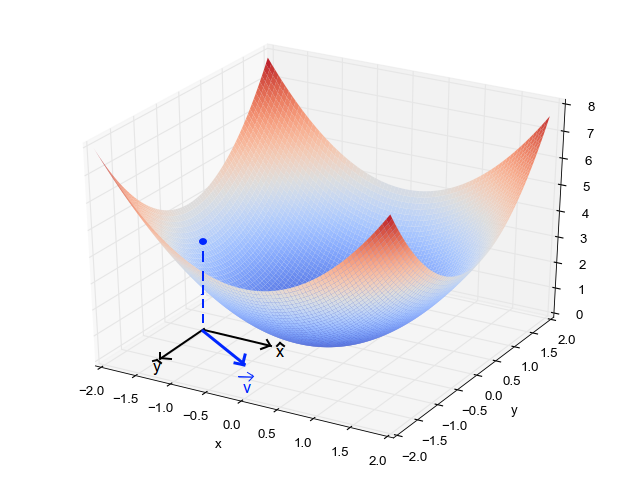
Gradient descent
El gradient descent es un algoritmo de optimización que se utiliza para minimizar una función de coste. El algoritmo funciona iterativamente para ajustar los pesos de la red neuronal. En cada iteración, el algoritmo calcula el gradiente de la función de coste con respecto a los pesos y actualiza los pesos en la dirección del gradient descent.
Si la función de coste se representa de la siguiente manera:
Entonces el gradient descent se puede representar de la siguiente manera:
Donde:
- es el vector de pesos.
- es la tasa de aprendizaje.
- es el gradiente de la función de coste con respecto a los pesos.
Algorimto de gradient descent
Tenemos los siguientes datos:
| 0 | 0 | 0 |
| 0 | 1 | 1 |
| ... | ... | ... |
| 1 | 1 | 1 |
Entonces el algoritmo de gradiente descendente se puede representar de la siguiente manera:
# Inicializar las variablesJ = 0 # Función de costodw1 = 0 # Derivada parcial de J con respecto a w1dw2 = 0 # Derivada parcial de J con respecto a w2db = 0 # Derivada parcial de J con respecto a balpha = 0.01 # Tasa de aprendizajem = 4 # Número de ejemplos# Iterar sobre los ejemplosfor i in range(m):# Calcular la prediccióny_predict = sigmoid(w1 * x1[i] + w2 * x2[i] + b)# Calcular la función de costo (loss entropy)J += - (y[i] * np.log(y_predict) + (1 - y[i]) * np.log(1 - y_predict))# Calcular las derivadas parcialesdw1 += (y_predict - y[i]) * x1[i]dw2 += (y_predict - y[i]) * x2[i]db += (y_predict - y[i])# Actualizar los pesosJ = J / mw1 = w1 - alpha * dw1 / mw2 = w2 - alpha * dw2 / mb = b - alpha * db / m
A continuación se presentan 3 variantes del algoritmo de gradiente descendente:
Batch gradient descent
Con este algoritmo actualizamos los pesos de la red neuronal al final de cada epoch.
- Función de optimización más lenta.
- Suele converger a un mínimo de la función de coste.
- Ideal para conjuntos de datos pequeños.
- El algoritmo tomará menos tiempo para completar un epoch, ya que solo se realiza una actualización de peso por epoch.
Mini-batch gradient descent
En mini-batch gradient descent, se calcula el gradiente de la función de coste con respecto a los pesos utilizando un subconjunto(mini-batch) de los datos de entrenamiento en lugar de todos los datos de entrenamiento.
- Se puede usar para entrenar un conjuntos de datos muy grandes.
- Función de optimización más rápida que batch gradient descent.
- Suele converger a un mínimo de la función de coste de manera menos directa.
- Ideal para conjuntos de datos grandes.
- El tamaño del mini-batch es un hiperparámetro, cuyos valores recomendados son 32, 64, 128, 256, 512, 1024, etc.
- El algoritmo tomará más tiempo para completar un epoch, ya que se realizan múltiples actualizaciones de peso por epoch.
Stochastic gradient descent
En el stochastic gradient descent, se calcula el gradiente de la función de coste con respecto a los pesos utilizando un solo ejemplo de los datos de entrenamiento en lugar de todos los datos de entrenamiento.
- Función de optimización más rápida que mini-batch gradient descent.
- No suele converger a un mínimo de la función de coste, aunque se puede aproximar.
- Ideal para conjuntos de datos grandes.
- El algoritmo tomará más tiempo para completar un epoch, ya que realizá una actualización de peso por ejemplo.
Momentum Gradient Descent
El momentum gradient descent es un algoritmo de optimización que se utiliza para minimizar una función de coste. El algoritmo es igual que el mini-batch gradient descent, pero con una diferencia. Este algoritmo implementa un concepto llamado Exponecial Weighted Average, que se utiliza para acelerar el proceso de aprendizaje.
- Esta función se aplica a cada uno de los pesos de la red neuronal al final de cada mini-batch.
- La función de optimización es más rápida que el mini-batch gradient descent.
Exponential Weighted Average
Exponential Weighted Average permite calcular la media de un conjunto de valores vecinos para suavisar la curva de aprendizaje. La fórmula es la siguiente:
Donde:
- es el nuevo valor suavizado.
- es el valor anterior.
- es el factor de suavizado.
- es el valor actual.
RMSprop
- Mantener un promedio móvil del cuadrado de gradientes
- Divide el gradiente por la raíz de este promedio.
- Esta función se aplica a cada uno de los pesos de la red neuronal al final de cada mini-batch.
- La función de optimización se comporta mejor que el momentum gradient descent.
Adam optimization algorithm
Este algoritmo se basa en el momentum gradient descent y el RMSprop. La fórmula es la siguiente: